HOW-TO VIDEOS
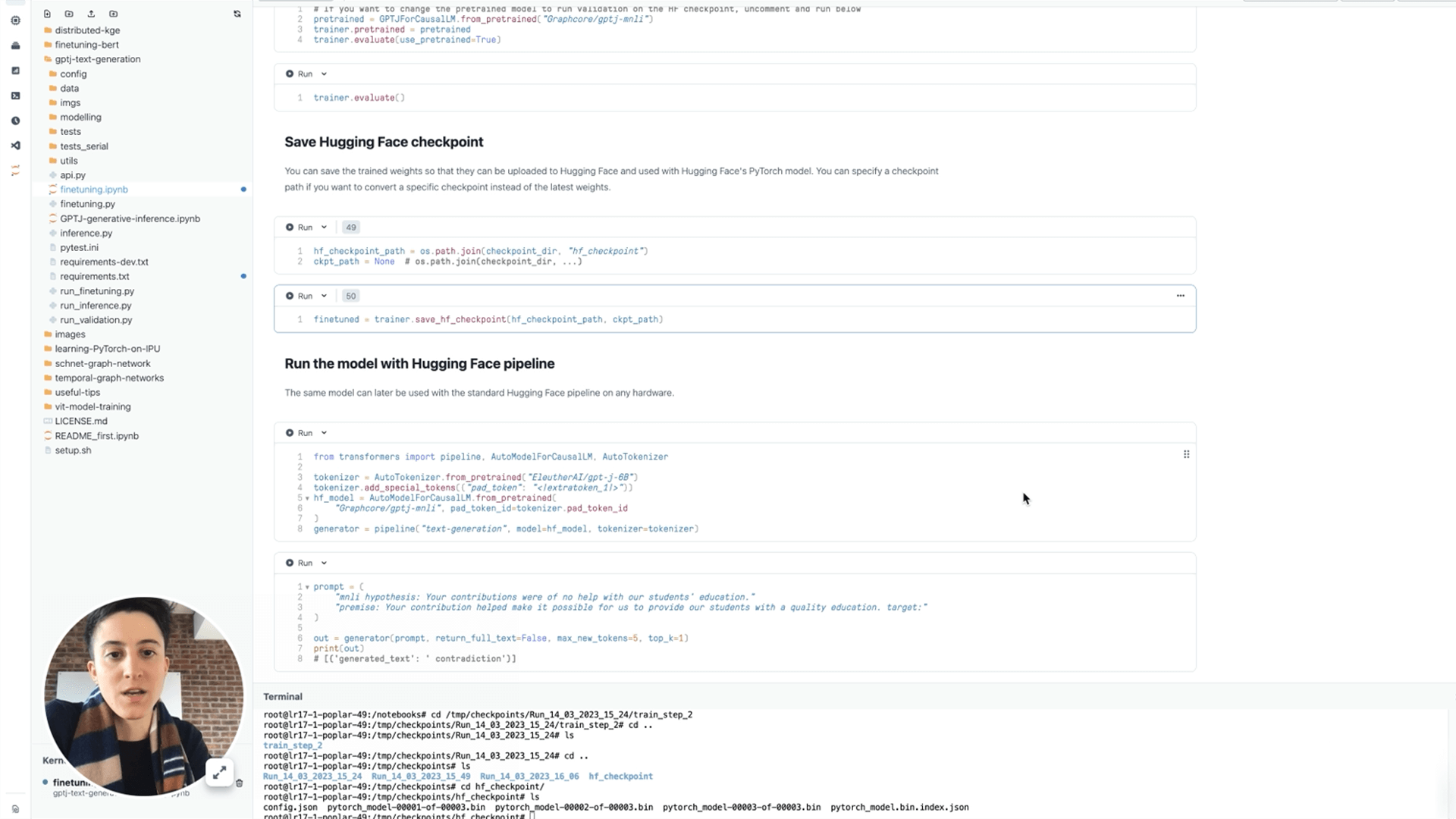
How to fine-tune GPT-J on the IPU
Fine-tuning GPT-J for NLP tasks using a text entailment example
What is GPT-J? A powerful, efficient alternative to large language models (LLMs) such as GPT-3 and GPT-4 for many NLP tasks.
In this video, Graphcore engineer Sofia Liguori walks through the process of fine-tuning GPT-J 6B on a Paperspace Gradient notebook (Google Colab alternative), powered by Graphcore IPUs.

How to run Baidu's PaddlePaddle on the IPU
Training and inference demo based on MNIST using PaddlePaddle
As the first open source deep learning platform in China, Baidu's deep learning platform PaddlePaddle is providing tools, services and resources required for rapid adoption and large-scale implementation of deep learning.
Li Qi, Senior R&D Engineer at Baidu, introduces the PaddlePaddle deep learning platform, its integration design with Graphcore's IPU, and demonstrates how to run the PaddlePaddle framework on IPU based on the MNIST model.

Running a Keras model on the IPU
Multi Layer Perceptron for weather forecasting
Graphcore's Alex Titterton explains how this model, built using Keras, can be easily trained using IPUs, obtaining a 5x speedup chip-for-chip in training throughput over the leading GPU without modification to the model or any hyperparameters.
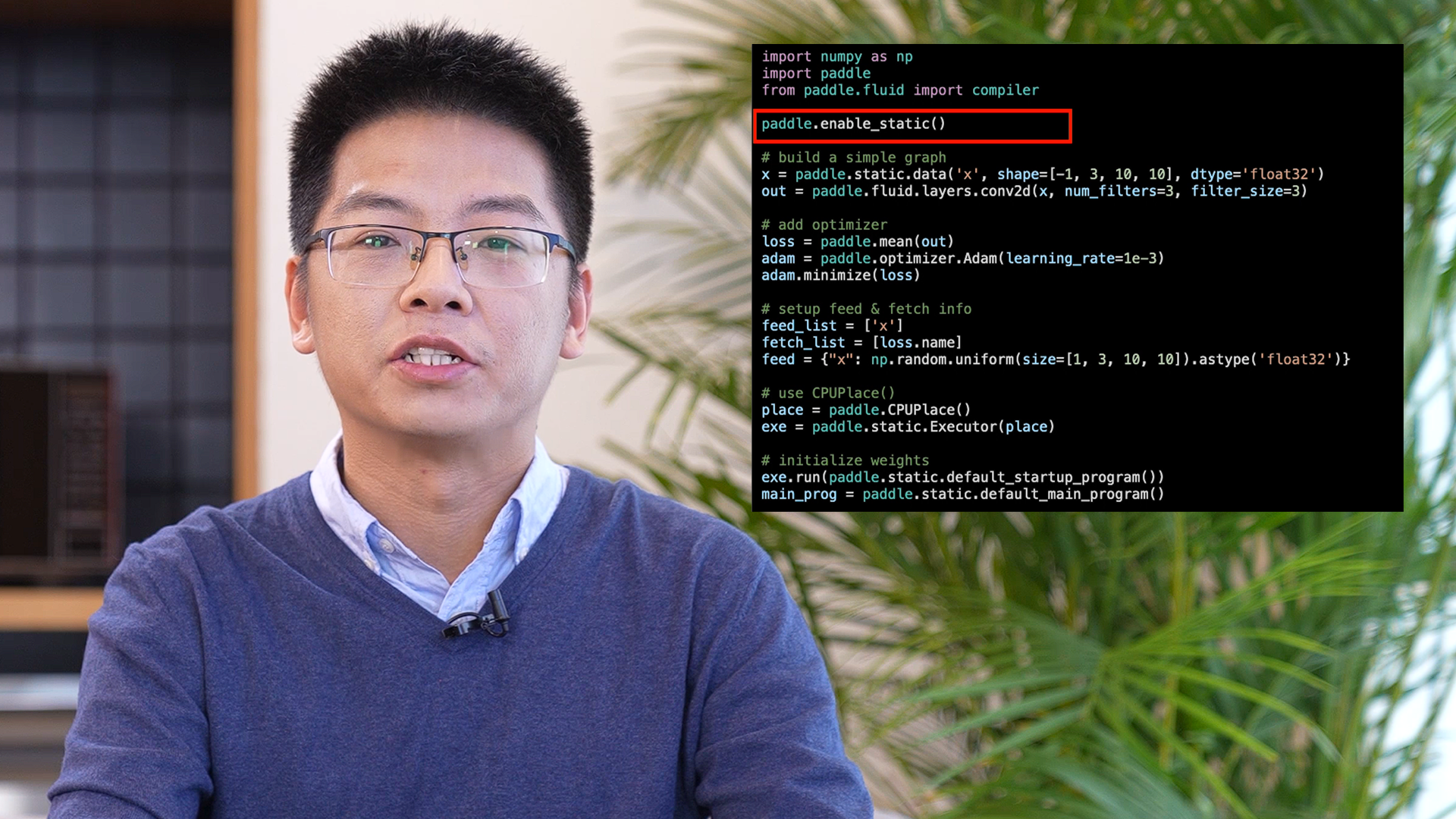
Getting started with PaddlePaddle on the IPU
Run BERT-Base training with Baidu's PaddlePaddle framework
PaddlePaddle is Baidu's deep learning framework for large-scale model training and high-performance inference tasks.
Han Zhao, software team lead at Graphcore China, provides an explanation and code walkthrough of running BERT-base training on the IPU using PaddlePaddle.

Getting started with PyTorch Lightning on the IPU
Run a PyTorch Lightning model with a single line of code
Introducing our initial release of PyTorch Lightning for the IPU. Developers can now use Lightning's ultra-fast, lightweight research framework to accelerate their training models with the performance advantages of the IPU.
Software Engineer Stephen McGroarty walks through Graphcore's PopTorch interface for PyTorch on the IPU, and demonstrates the simplicity of running PyTorch Lightning code.

Hands-on: Running PyTorch models on the IPU
Discover how to run PyTorch models faster on Graphcore systems
Graphcore has created PopTorch™ – our own set of extensions for PyTorch. PopTorch allows developers to run their PyTorch models directly on IPU hardware by changing just a few lines of code.
In this on-demand webinar, Mihail Popa introduces core PopTorch functionality, explains how to port your PyTorch application and provides tips on accelerating training.

Programming on the IPU 101
Learn the fundamentals of how to program IPU systems with the Poplar SDK
By co-designing the Poplar graph programming framework with IPU hardware, Graphcore has created an easy-to-use and flexible software development environment that lets engineers explore new approaches to machine intelligence.
In this on-demand webinar, Graphcore’s Helen Byrne introduces the Poplar SDK and fundamental IPU programming concepts, as well as how to port models built with standard machine learning frameworks.
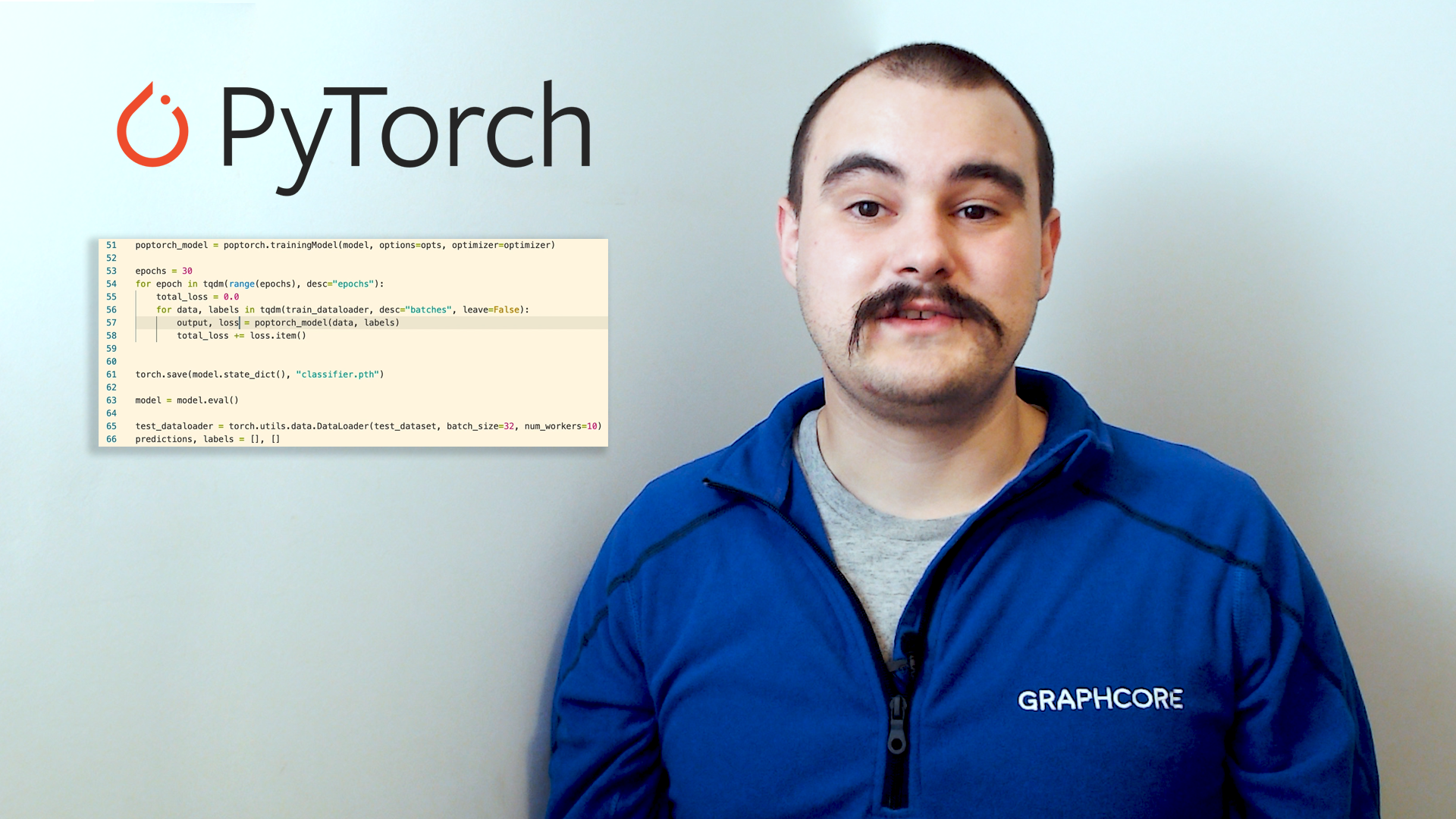
Getting started with PyTorch for the IPU
Running a basic model for training and inference
AI Customer Engineer, Chris Bogdiukiewicz introduces PyTorch for the IPU. With PopTorch™ - a simple Python wrapper for PyTorch programs, developers can easily run models, directly on Graphcore IPUs with a few lines of extra code.
In this video, Chris provides a quick demo on running a basic model for both training and inference using a MNIST based example.
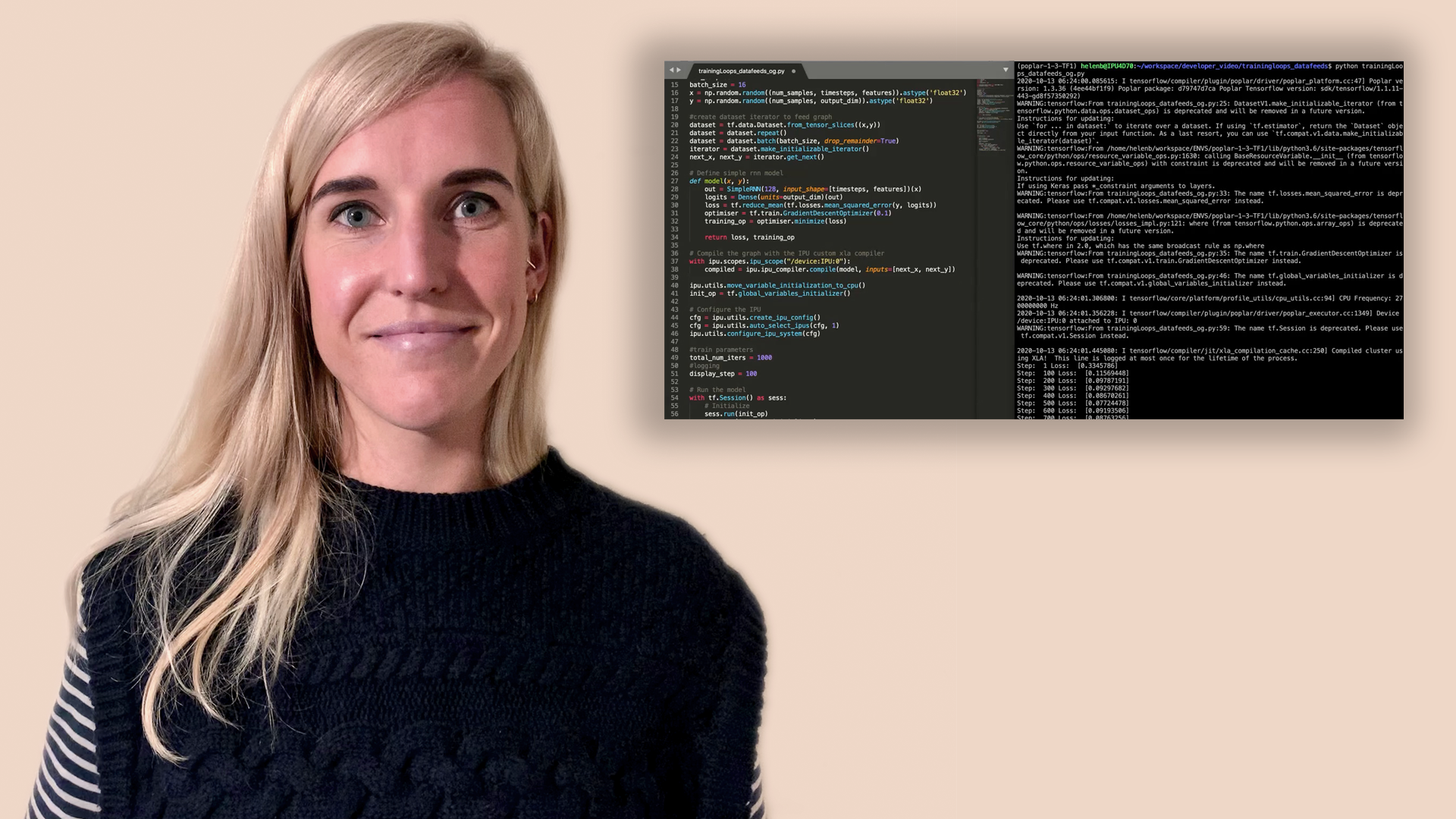
Using data feeds and training loops on the IPU
Optimising IPU training performance in TensorFlow
The Graphcore IPU support for TensorFlow provides three mechanisms to improve the training performance: training loops, data set feeds, and replicated graphs. In this video, Helen Byrne explains the technique of placing training operations inside a loop, so they can be executed multiple times without returning control to the host.

Fundamentals of Bulk Synchronous Parallel Execution
A programming methodology for parallel algorithms
Alex Titterton explains the principles and implementation of Bulk Synchronous Parallel compute on Graphcore's IPU.
While the technique is commonly used in large compute clusters, the IPU is the first single processor to be based around BSP. BSP consists of three phases: Compute, Synchronise & Exchange. BSP is applied both inter-IPU and intra-IPU, enabling large scale, distributed computation of AI models on Graphcore systems.

Evaluating Batch Sizes for IPUs
Training models at reduced batch sizes
Graphcore AI Applications Specialist, Jose Solomon examines the impact of batch size on training a model on the IPU.
In this video Jose shows how Graphcore technology can perform tasks using simplified optimizers at low batch sizes, where larger batch sizes would necessitate much more complex optimizers.
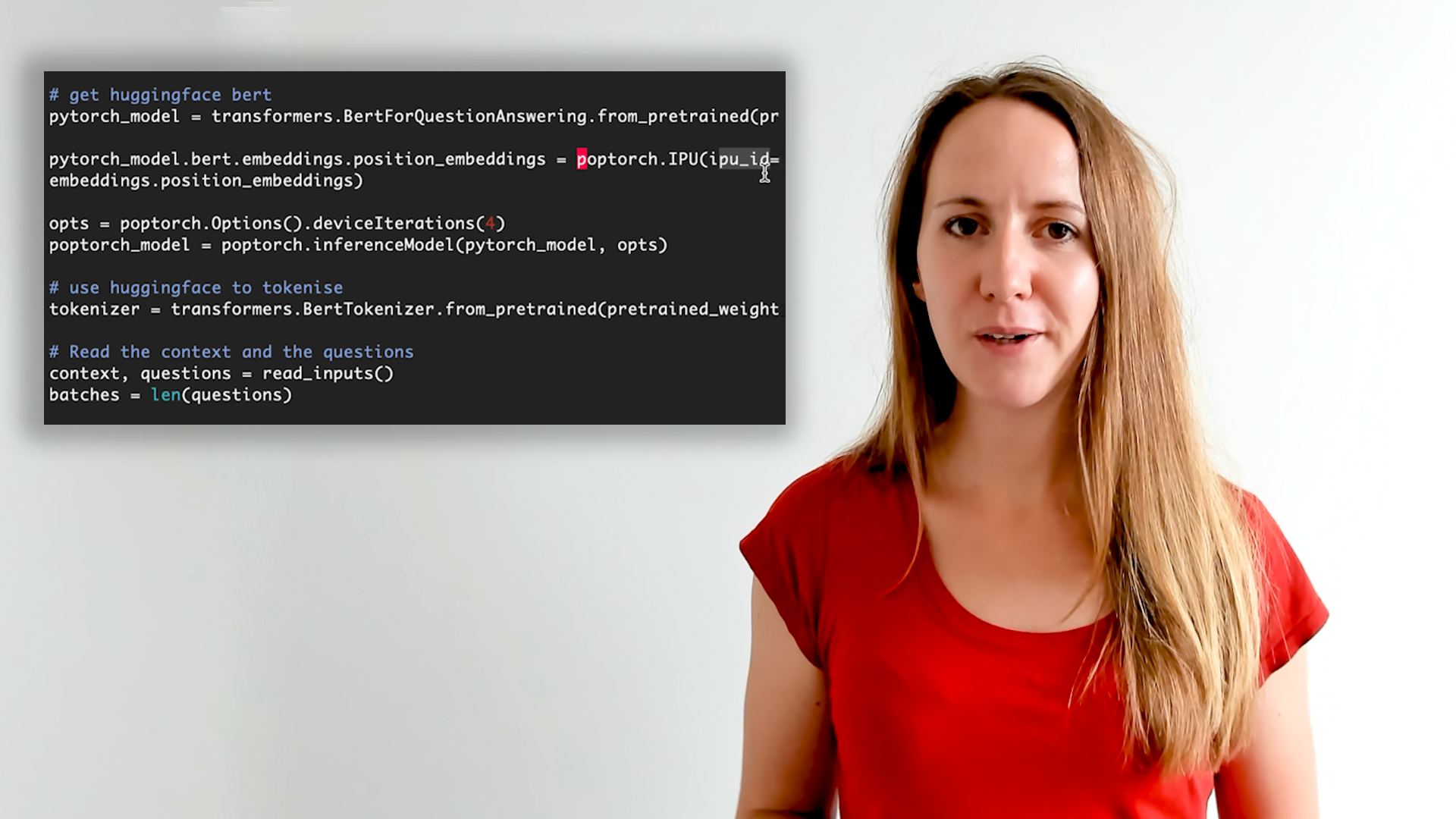
Running PyTorch on the IPU: NLP
Hugging Face BERT-Medium inference fine-tuned on SQUADv2
Graphcore AI Engineer Kate Hodesdon demonstrates how to develop PyTorch models for the IPU using a Hugging Face BERT-Medium model example.
This demo also introduces PopTorch – a lightweight set of extensions to PyTorch that allows developers to run PyTorch directly on the IPU. PopTorch makes IPU directly accessible from within PyTorch code – meaning that developers can take advantage of IPU hardware acceleration without learning a whole new framework.

Getting started with PopVision™
An introduction to the PopVision™ Graph Analyser
Graphcore Customer Engineer Marie-Anne Le Menn introduces the PopVision™ Graph Analyser, including code walkthrough.
PopVision™ is used to analyse the programs built for and executed on Graphcore’s IPU systems. It can be used for analysing and optimising the memory use and performance of programs.

Fundamentals of the IPU and Poplar®
Poplar demo using a basic addition example
Field Applications Engineer Alex Titterton provides a quick introduction to Graphcore's Poplar® software.
This walkthrough covers the essentials of IPU architecture from a software perspective and finishing with a demonstration of a simple addition example running on the IPU using the Poplar C++ framework.
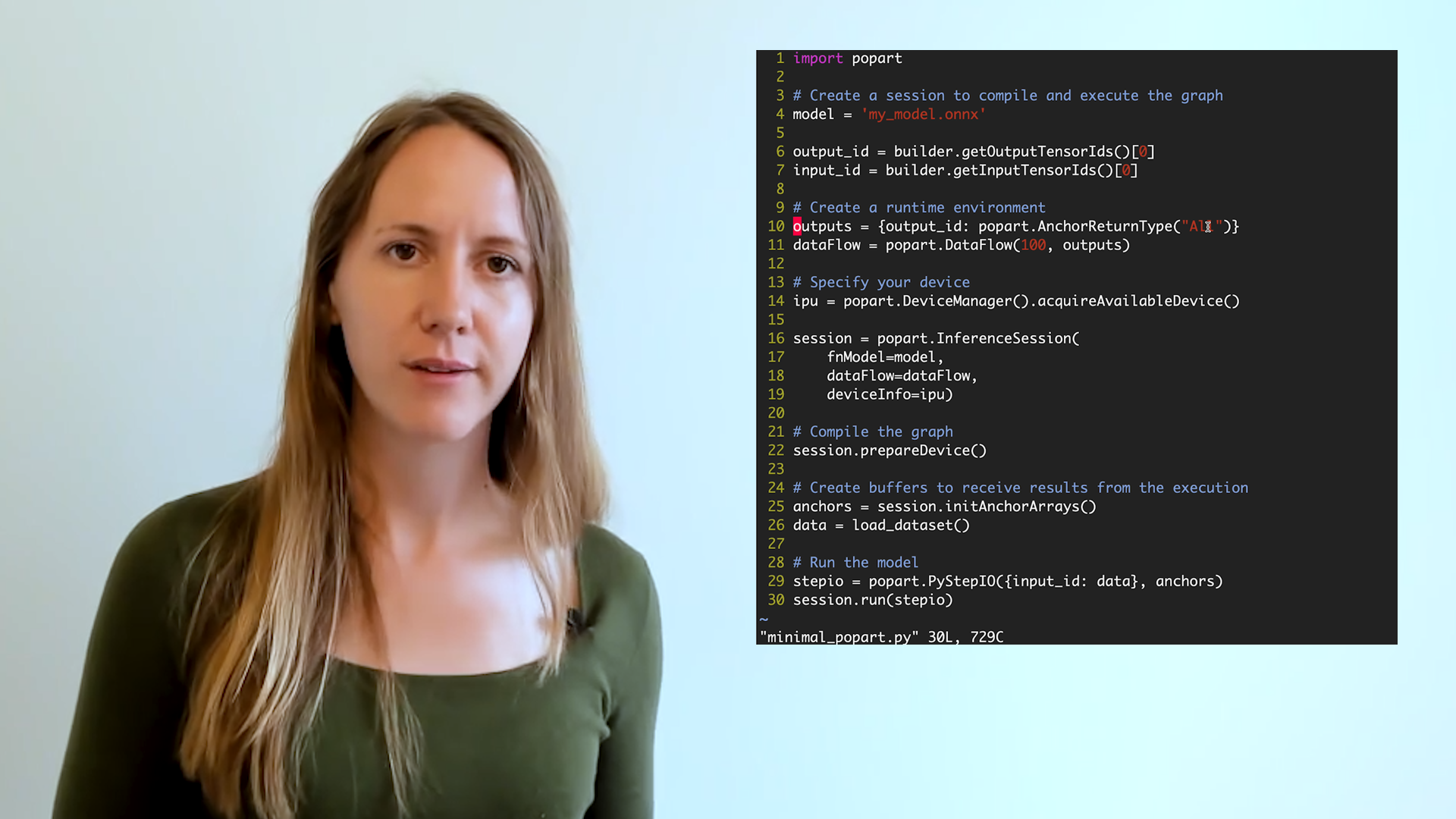
Getting started with PopART™
Graphcore's machine learning framework
Graphcore AI Engineer Kate Hodesdon introduces PopART™. The Poplar Advanced Run Time (PopART) is part of the Poplar SDK for implementing and running algorithms on networks of Graphcore IPU processors.
It enables you to import models using the Open Neural Network Exchange (ONNX) and run them using the Poplar tools. ONNX is a serialisation format for neural network systems that can be created and read by several frameworks including Caffe2, PyTorch and MXNet.

Running TensorFlow on the IPU: Probabilistic Modelling
Markov Chain Monte Carlo (MCMC) model demo
Graphcore Senior AI Engineer Alex Tsyplikhin demonstrates the ease of moving a TensorFlow model, originally designed to run on a GPU, onto Graphcore's IPU processor.
In this walkthrough, Alex uses the Markov Chain Monte Carlo (MCMC) method, common in the financial service industry where it is used for tasks such as risk estimation and option pricing.