Jan 12, 2023
Jan 12, 2023
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamOne of the quickest and easiest ways to build a natural language processing (NLP) application is to use the Hugging Face ecosystem to rapidly prototype your solution.
In this blog, I’ll show you how, with 10 lines of familiar Hugging Face code, you can build an NLP application for a Named Entity Recognition (NER) task on Graphcore IPUs that can identify words associated with illnesses as fast as you can type.
You can follow along with this blog using a Paperspace Gradient Notebook, powered by Graphcore IPUs.
Paperspace lets you test, develop and deploy in a single Jupyter notebook environment, with pricing to suit your need for speed and scalability depending on the lifecycle of your project. Users can also take advantage of the IPU free tier on Paperspace.
For more details on Graphcore and Paperspace Gradient Notebooks, see our blog.
Also, be part of the conversation:
Developments in the ecosystem over the last few years, mean that developers can now pick an off-the-shelf model that is already fine-tuned on a task similar to the one they are interested in.
You can quickly evaluate this model interactively in a notebook or through an app, then systematically, with a dataset that is more representative of the specific task you want to address.
The days of starting from a blank sheet are long gone. The way to build an app that uses deep learning today is to install libraries, and I don’t mean PyTorch or TensorFlow, I mean 🤗 Transformers and Datasets. These libraries grant instant access to validated implementations of most standard model architectures, pre-trained checkpoints, and standard and custom datasets.
To use 🤗 Transformers on Graphcore IPUs, pip install the optimum-graphcore integration:
These extensions implement many models that can be used to solve NLP problems. The simplest way to start is with a pre-trained model that has already been fine-tuned on the correct task.
In this blog post, we are going to be doing Named Entity recognition (NER) which is a type of token classification: we need to assign a class to each word in an input prompt.
The simplest way to do this is to use the `pipeline` API provided by 🤗 Transformers and the optimum-graphcore:
In those 3 lines of code the `pipeline` function has:
It has never been easier to get started with deep learning application, and it has never been easier to access new, cutting-edge hardware. The only change that was required to go from using a CPU or GPU to an IPU is the import of the package, all the rest can remain the same. The `optimum-graphcore` library is open source and developed in the open, letting you peer under the hood of how models are implemented, and giving you licence to modify and adapt the library to your needs (or just raise an issue on our GitHub repository).
If you are following along in a Paperspace Notebook, you can keep prompting the `ner_pipeline` with new prompts to quickly classify new tokens.
In 2023 no-one wants to be interacting with a script. To successfully solve the underlying business problem that requires NER you will need to make that service available to others, either as an app or as an API endpoint. The fastest way I’ve found to prototype a solution is with .
Gradio let’s you build a very simple WebUI which can live directly in your notebook or standalone in your browser. In addition, it benefits from a very tight integration with the Transformers library.
To install gradio simply do:
From there creating a simple WebApp that lets you enter a prompt and see the output requires just a couple of additional lines of code:
Because the NER pipeline is not supported by the `Interface.from_pipeline` method, we need to write our own interface. Thankfully, this is very easy to do:
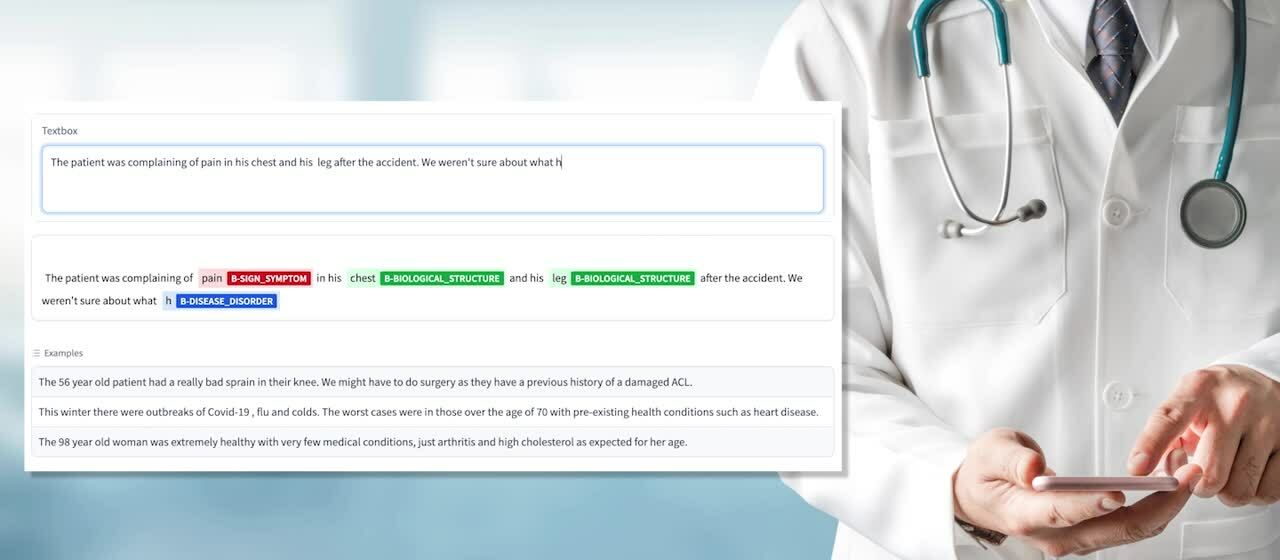
We connect an `inputs` TextBox to the UI element which will highlight the text with the output of the model. For convenience we also add some examples, and once we connect all the elements, every time the text in the input box changes, the highlighted output will be displayed. Enabled by the speed of IPUs the model response is fast enough to let give a great interactive experience.
The ability to rapidly prototype a solution and display it interactively to be tested and assessed by non-technical colleagues is great to quickly get feedback without wasting a lot of time on developing features that will not be used.
The initial model that is loaded by the pipeline is unlikely to be quite what you need. Thankfully we are not limited to the default model.
A quick look on the shows that we have almost 6000 pre-trained models to choose from on the task of token classification. These models might have different architectures or may be trained or fine-tuned on different datasets to tackle more specific tasks. You might find models trained for other languages or to recognise different tokens.
While not all architectures are supported on the IPU we are to make them available to you.
Now, it is trivial to load a model from the Hub using the pipelines interface, simply pass the model name as a parameter to the function when creating the pipeline:
This model is fine-tuned to recognise bio-medical entities. It can be used to detect words which may be of clinical interest when diagnosing or assessing a patient. Integrating this model into the Gradio app that we wrote above we get the following output:  If you were working in healthcare you might use a little app like this to draw attention from staff to the relevant part of a written request, or you might use it to do automated tagging to facilitate retrieval of records when a doctor is looking through a patient history. The exact use of the model will depend on what you are trying to achieve.
If you were working in healthcare you might use a little app like this to draw attention from staff to the relevant part of a written request, or you might use it to do automated tagging to facilitate retrieval of records when a doctor is looking through a patient history. The exact use of the model will depend on what you are trying to achieve.
Integration with the Hugging Face Hub lets you leverage the fast, low-cost inference of the IPU with your models which have already been trained. If you already had a training pipeline on GPU, it is very easy to swap out expensive and difficult to access GPUs with a cheaper and equally fast alternative in the IPU, without needing to alter your workflow.
The final step of the model lifecycle that you can address very easily with the Transformers library and the IPU is Fine-tuning. If you are considering deep learning it is likely that you have custom data that you would like the model yourmodel perform particularly well on. To do so, we will see how the model you have loaded can be fine tuned.
If you are familiar with the Trainer class provided by the 🤗 Transformers library, this section will be very straightforward to follow. The steps are the same for IPU and GPU except for the training arguments and the configuration options which require IPU specific parameters to enable you to leverage the computational architecture and multi-device parallelism of the IPU.
To fine-tune the model we loaded from the hub, you first need to load your custom dataset using the 🤗 datasets library:
This might take a bit of data manipulation but once loaded, the dataset can be tokenised and batched so that it can be processed by the model:
So far, code has been unchanged between GPUs and IPUs. However, the computing architecture of the IPU means that a few more steps are needed to correctly batch the data and ensure effective training. Pytorch on the Graphcore IPU only supports fixed size tensors, this means that all batches of sentences need to have the same length.
To achieve this we write a function to tokenize and align the labels and map this function to our dataset:
With those changes the data and labels are ready for training on the IPU. What remains is to load the training model and some IPU specific arguments before we can create the trainer:
Now that we have selected a model to fine-tune we need to set the hyper parameters of the optimizer and the IPU specific settings;
The standard training arguments of the `transformers` library are expanded to include IPU- specific parameters which will impact the efficiency and effectiveness of training convergence. The “per device train batch size”, “gradient accumulation steps” and “pod_type” arguments control the number of samples which get dispatched to each replica between each weight update and have a significant impact on the throughput and convergence of the model.
Finally, we load the IPUConfig corresponding to the model we want to train. Graphcore provides 33 preset configurations on its , which will let you make the most of the hardware that you have access to.
This configuration object contains IPU specific settings which will not impact the convergence of a training model but may affect throughput or latency of a model the execution.
Once you have created the dataset, tokenizer, model, training arguments and IPU configuration objects you are ready to set up the IPU trainer:
Your model is trained! You can now save a checkpoint or even upload it to the Hugging Face hub to share it with others in your company or the wider community. You can also try changing the `pod_type` argument above to match the number of IPUs you have available: the larger your system the faster the model will run, with no other code changes.
I hope that this blog post convinced you that trying out new hardware didn’t mean uprooting your entire workflow: it takes as little as 10 lines of code to prototype a web-app which recognises and classifies words in real time. With 🤗 Transformers and the 🤗 Hub we can have GPU-IPU hybrid workflows and leverage the strengths of each hardware.
Beyond Named Entity Recognition, many other NLP tasks can now be tackled by assembling simple and intuitive blocks provided by high-level libraries. Try out some of our examples on Paperspace which range from image classification, image generation, audio processing and GNNs.
Share:


.png)