Jun 30, 2021 \ AI, Corporate, Benchmarks
Jun 30, 2021 \ AI, Corporate, Benchmarks
共有:
この度Graphcoreは、AI业界で最も広く知られている比较ベンチマークプロセスのMLPerfTMによる学习评価を初めて受けました。
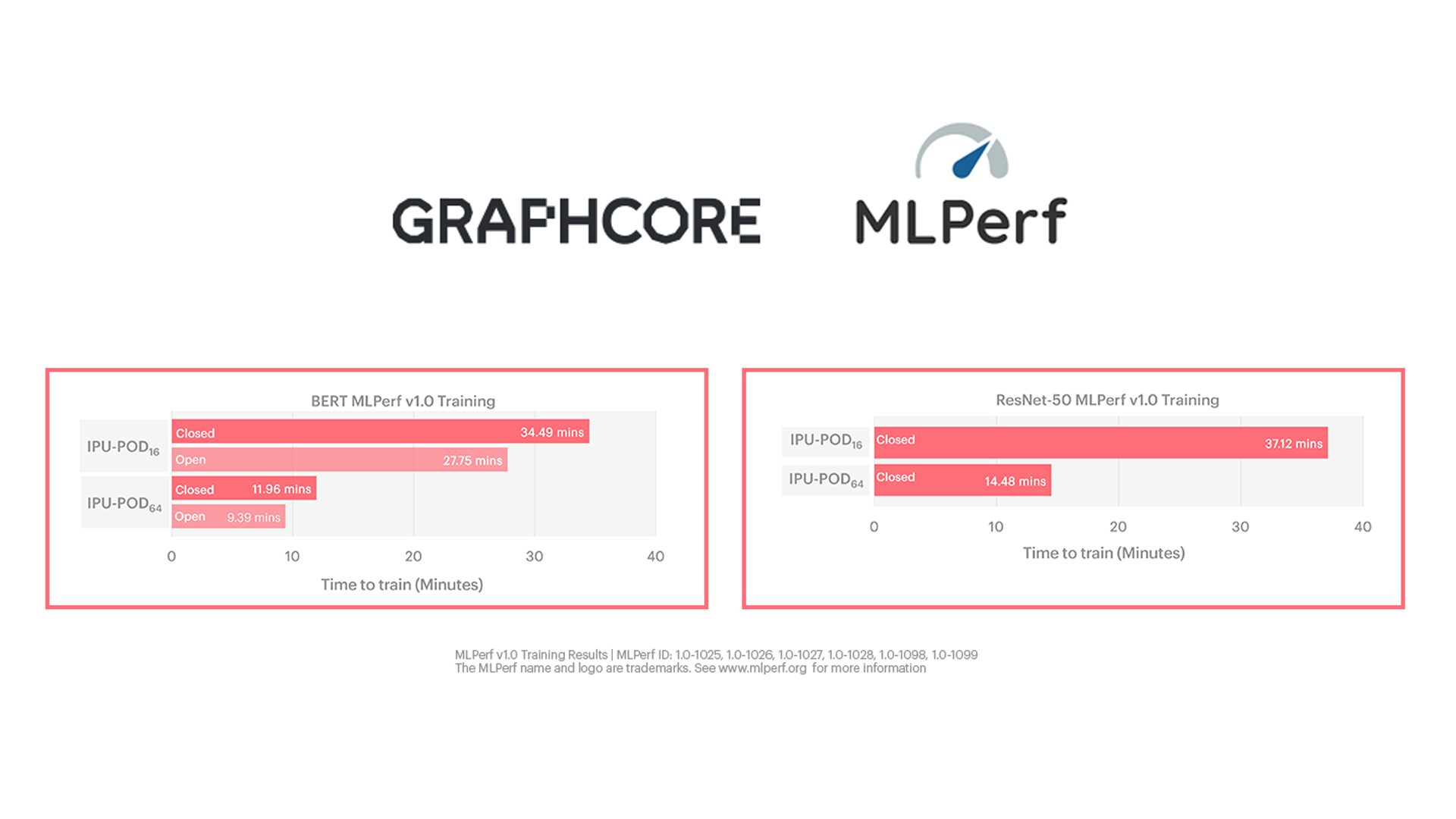
その结果、IPU-POD64においてBERTの学习时间はわずか9分强、ResNet-50の学习时间は14.5分と优れた结果が得られました。 これはスーパーコンピュータレベルのAIパフォーマンスです。
MLPerfでは、市贩されているGraphcoreのシステムとNVIDIAの最新システムとの比较も示されており、1ドルあたりのパフォーマンス指标では当社が优位に立っています。
Graphcoreのシステムが単に次世代のAIにおいて优れていることだけでなく、现在最も広く使用されているアプリケーションにおいても优れていることがサードパーティによって确认されたということは、お客様にとって大きな意味を持ちます。
成熟したソフトウェアスタックや革新的なアーキテクチャ、高パフォーマンスのシステムを夸るGraphcoreがAIコンピュートの分野で注目すべき公司であることは、もはや疑いの余地がありません。
Graphcoreが创设メンバーとして参加しているMLPerfは、によって监督されているコミュニティで、他にも人工知能分野のメンバーや関连会社、非営利団体、営利公司が50社以上参加しています。
MLCommonsの任务は「机械学习のイノベーションを加速させ、社会へのプラスの影响を増大させること」であり、当社はこの伟大な目标を全面的に支持しています。
学习と推论の结果は四半期ごとに、交互に発表されます。Graphcoreが提出した最新の学习ラウンドの生データは、でご覧いただけます。
今回当社が初めて提出したMLPerf(学习バージョン1.0)では、アプリケーションベンチマークの主要カテゴリーである「画像分类」と「自然言语処理」に焦点を当てることにしました。
MLPerfの画像分类ベンチマークでは定番のResNet-50バージョン1.5モデルが使用され、全评価対象に共通する规定の精度に达するまでImageNetデータセットで学习されます。
NLPについては、BERT-Largeモデルが使用されており、セグメントは全学习コンピュートワークロードの约10%に相当し、Wikipediaデータセットを使用して学习されます。
当社が、ResNet-50とBERTを用いた画像分类とNLPに提出することを决めた背景には、それらをアプリケーションやモデルとして最も频繁に使用するお客様や、潜在的なお客様の存在が大きく影响しています。
MLPerfにおける当社の强力なパフォーマンスは、当社のシステムが今日のAIコンピュートの要求に応えることができることを示す、さらなる証拠です。
今回、Graphcoreの2つのシステム、IPU-POD16 とIPU-POD64でMLPerfの学习评価を受けました。
この2つのシステムはどちらも、製造中のお客様にすでに出荷されているものなので、プレビューではなく「市贩」のカテゴリーにエントリーしました。これは、MLPerfへの初の提出としては大きな成果です。
IPU-POD16は、Graphcoreが开発したコンパクトな5Uサイズのシステムで、IPU AIコンピュート能力の构筑を始めた公司のお客様向けに手顷な価格で提供されています。このシステムは4台の1U IPU-M2000と1台のデュアルCPUサーバーで构成され、4ペタフロップスのAI処理能力を発挥します。
もう一方のスケールアップしたIPU-POD64は、16台のIPU-M2000と台数を自由に选べるサーバーで构成されています。GraphcoreのシステムではサーバーとAIアクセラレータが分散されているので、お客様は実际のワークロードに応じてCPUとIPUの比率を指定できます。例えばコンピュータビジョンのタスクは、一般的に自然言语処理よりもサーバーへの要求が高くなります。
そこでMLPerf用に、IPU-POD64はBERTにサーバーを1台、ResNet-50にサーバーを4台使用しました。そして各サーバーにAMD EPYC? CPUを2つ搭载しています。
MLPerfにはオープンとクローズドの2つの提出部门があります。
クローズド部门では、モデルの実装やオプティマイザのアプローチが全く同じであることが提出者に厳格に要求され、これにはハイパーパラメータの状态や学习エポックの定义も含まれます。
オープン部門は、クローズド部門と全く同じモデルの精度と品質を確保しつつ、モデルの実装に柔軟性を持たせることでイノベーションを促進することを目的としています。その结果、さまざまなプロセッサの能力やオプティマイザのアプローチに合わせて微調整された、より高速なモデルの実装が後押しされます。
当社のIPUのような革新的なアーキテクチャの场合、オープン部门の方が当社のパフォーマンスがより顕着に表れる思いますが、当社はオープンとクローズドの両方の部门に提出することを选択しました。

これらの结果からは、仕様に関する制约の多い、従来の常识を破るようなクローズド部门でもGraphcoreのシステムは高いパフォーマンスを発挥していることがわかります。
さらに印象的なのはオープン部门での结果で、当社のIPUとシステムの能力を最大限に活用した、最适化のようなものを示すことができました。これらの事実は、お客様がパフォーマンス向上のメリットを享受できる、现実的なユースケースをより如実に反映するものです。
MLPerfは比较ベンチマークとして知られ、多くの场合は、あるメーカーの技术を别のメーカーの技术と比较して评価するときに基準として用いられます。
事実、直接比较することは复雑になることがあります。 今日のプロセッサやシステムのアーキテクチャは、比较的シンプルなシリコンから高価なメモリを搭载した复雑なスタックチップまで多岐にわたっています。
お客様と同じように当社も、1ドルあたりのパフォーマンスに基づく结果を一番有益な情报として注目します。
GraphcoreのIPU-POD16は5Uシステムで、は149,995ドルです。すでに説明したようにこのシステムは、それぞれに4つのIPUプロセッサを搭载した4台のIPU-M2000アクセラレータと、业界标準のホストサーバーで构成されています。MLPerfで使用されているNVIDIA DGX-A100 640GBは、小売希望価格が约300,000ドル(市场情报と公表されている再贩业者の価格に基づく)の6Uボックスで、DGX A100チップが8个搭载されています。
それに対してIPU-POD16は半分の価格です。アクセラレータに着眼してこの结果を见た场合でも、当社のシステムではIPU-M2000 1台がA100-80GB 1台と同じ価格であり、より细かく见ればIPU 1台の価格は4分の1であることがわかります。
当社が行ったMLPerfの比较分析では、制约の厳しいクローズド部门の结果を採用し、标準化してシステム価格にしています。
ResNet-50とBERTの両方において、Graphcoreのシステムの方がNVIDIAの製品よりも1ドルあたりのパフォーマンスにおいて着しく良いことは明らかです。
IPU-POD16が示した1ドルあたりのパフォーマンスは、ResNet-50の学习では1.6倍、BERTでは1.3倍となっています。


これらのMLPerfのチャートは、実际のGraphcoreのお客様が体験していることを反映しています。つまり、AI向けに构筑されたIPUのアーキテクチャにより、当社のシステムの経済的侧面がAIコンピュートの目标达成に役立つと同时に、次世代のモデルや技术の未来を切り开いているということです。
初めて提出したMLPerfの評価でこのような结果が得られたことを、当社はとても誇りに思っています。このような结果を得るために、当社のカスタマーエンジニアリンググループから選ばれた少人数のエンジニアチームをはじめ、全社を挙げてとても熱心に取り組んできました。
また、今回の参加を支えるあらゆる改良と最适化が现に当社のソフトウェアスタックに组み込まれていることを踏まえると、当社が提出した意义はいっそう深くなります。世界中のGraphcoreユーザーはすでに、BERTやResNet-50よりもはるかに多くのモデルでMLPerfの評価结果から恩恵を受けています。
当社は学习ラウンドと推论ラウンドの両方において、MLPerfに継続して参加することを约束します。そして、より良いパフォーマンス、より大きなスケール、より多くのモデルの追加という3つの目标を目指します。
当社が継続的なソフトウェアの改良に注力していることは、Poplar SDKの最近のリリースで确认されたベンチマークの进歩にも表れています。2020年12月から2021年6月までの半年间に行われた3回のアップデートで、当社はResNet-50で2.1倍、BERT-Largeで1.6倍、ResNetよりもさらに高精度を重视したコンピュータビジョンモデルであるEfficientNetで1.5倍のパフォーマンス向上を実现しました。

Graphcoreの研究チームは、ソフトウェアの継続的な改良を追求すると同时に、现行モデルと次世代モデルの可能性の限界に挑戦しています。彼らが最近発表した「EfficientNetの効率を高める」や「アクティベーションのプロキシ正规化によるCNNにおけるバッチ依存性の排除」は、MLPerfの评価に向けた準备作业に直接関连しており、Graphcoreのお客様だけでなく、より広いAIコミュニティに利益をもたらすものです。
现在最も広く使用されているAIモデルでのパフォーマンスを示すために、最初にResNet-50とBERTでMLPerfに提出することが重要でした。
しかしGraphcoreのIPUとそれを搭载したシステムは、次世代のAIアプリケーションを得意とし、レガシーなプロセッサアーキテクチャの制限を受けずに、ユーザーが新しいモデルや技术を开発できるように设计されています。
その一つがEfficientNet-B4です。これはより高度な、しかし现在も広く使用されているコンピュータビジョンモデルで、1ドルあたりのパフォーマンスの面でIPUとGPUの间には大きな差があることを示す良い例です。

MLPerfがこのような革新的なモデルと歩调を合わせながら、今日の最も一般的なユースケースも同时に反映していくことで、お客様やAI业界が恩恵を受けることになると当社は考えます。
Graphcoreは今后も、当社の技术を利用する人のためだけでなく、利用していない人のためにも、积极的で进歩的なMLCommonsメンバーとして活动していきます。
差し当たり、初めての提出にはとても満足しており、次の提出に向けてすでに準备を进めています。
共有:

